Welcome to the eighth blog in a series on machine learning. Once again, this material is a supplement to the introductory course in machine learning on Udacity. We will be looking into feature selection and how it can affect the quality of a classifier.
Bigger != Better
As you may expect, giving a classifier more data will increase it’s ability to predict future test cases. However, regardless of the amount of data provided to a classifier, having too many features can degrade the performance. This degradation occurs because the classifier will overfit to the feature set as the number of features grow larger and larger. This idea will be further illustrated later to help give a better understanding.
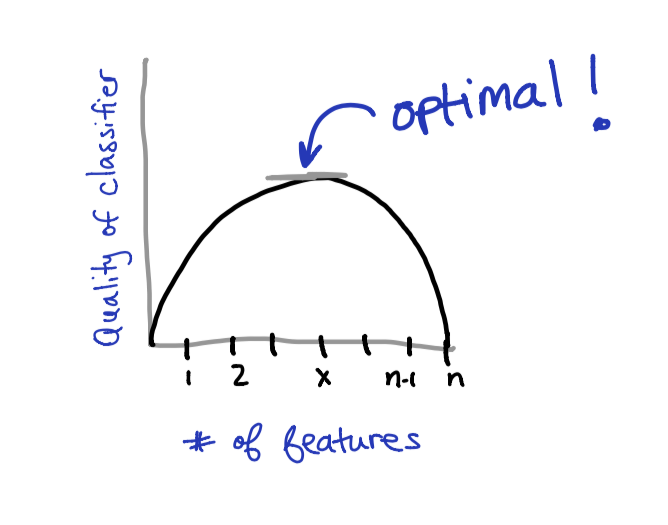
The goal of this article is to assess the optimal number of features to include in a classifier as well as help you decide which features are most favorable when building a classifiers.
Bias vs Variance
Before jumping into the details of feature optimization, let’s first address the difference between high bias and high variance. These two terms are important adjectives that can be used to describe how data is classified.
A classifier with a high bias means that the classifier is trained with a large amount of generality. This means that the classifier will be associating labels with few features and is not sensitive to noise in the data. Therefore, if one aims to achieve a high level of bias and preserve accurate predictions, then it is critical to select the best features in the dataset.

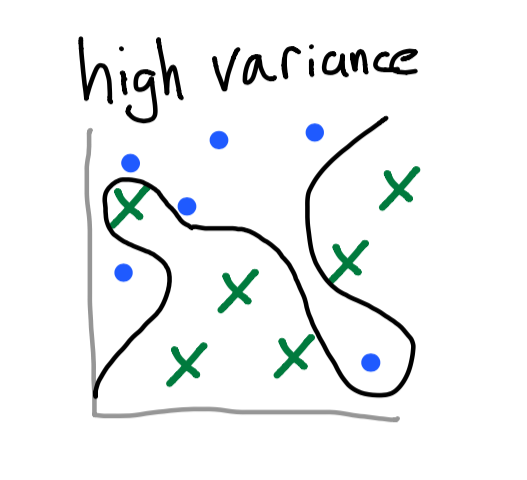
Likewise, a classifier with high variance means that your classifier is overfitting to the data. This can occur when there are too many features and the line of best fit is too sensitive. Since the classifier is not generalized, it will be much more difficult to accurately predict unseen test data.
Lasso in SKLearn
Lasso is a tool that will automatically select the best performing features, and train on this subset of data. This is very similar to the TFIDFVectorizer used in the previous post. When we were analyzing the blog posts, there were some common words that were features (such as “a”, “and”, “that”, etc). The TFIDFVectorizer was able to detect that these features were not useful to the classifier and therefore not use them in the fitting step.
When we experiment with a contrived example, the effects of the Lasso is quite clear. The unimportant features are scaled to 0, while the more defining features are weighted more heavily.
from sklearn.linear_model import Lasso
l = Lasso()
l.fit([[0, 1, 10], [0, 1, 23], [0, 1, 100]], [1, 13, 59])
print("Coefficient: " + str(l.coef_))
❯ python lasso.py
Coefficient: [ 0. 0. 0.62748274]
While observing the training data, we can see that the first two features are always 0 and 1. Since these features are not very helpful in describing the label, the Lasso algorithm ignores it by multiplying the feature by the zero coefficient. Therefore, we see that the optimal number of features in this case is 1.
Conclusion
Your predictions are only as good as the data used. Using feature selection can not only lead to more accurate predictions, but also improve the performance of the algorithm.
Also be aware of the bias vs variance tradeoff. Having too much of one can lead to unexpected results. Lasso, TFIDFVectorizer, and other SKlearn libraries can aid in feature removal so that only the unique data has the most weight in a decision.